Polars 是基于 Rust 开发的开源 DataFrame 库,专为 Python
中的高性能数据操作和分析而设计。通过并行处理和内存优化技术,达到了显著优于
Pandas 的性能。
Pandas 与 Polars 性能对比
通过 csv 写入(write_csv)、csv
读取(read_csv)、列选择(select_columns)、行筛选(filter_rows)、行排序(sort_rows)、空值填补(fill_na)、统计量计算(calc_stats)这
7 类 Benchmark 在 Pandas 和 Polars 下的耗时,评估这 2
个库的性能。评估结果如下图表所示,所有运行结果均基于 Lenovo Legion
R9000P 2023(AMD R9-7945HX,96GB RAM,安静模式)得到。
| csv 写入(write_csv) |
68.47109769999952 |
2.4320810999997775 |
| csv 读取(read_csv) |
18.033977799997956 |
1.293282899998303 |
| 列选择(select_columns) |
2.6878174000012223 |
1.3185502999986056 |
| 行筛选(filter_rows) |
20.69887430000381 |
1.9661064000029 |
| 行排序(sort_rows) |
5.450892100001511 |
1.174701100004313 |
| 空值填补(fill_na) |
4.529551200001151 |
0.7351737999997567 |
| 统计量计算(calc_stats) |
6.443044399995415 |
0.5910871000014595 |
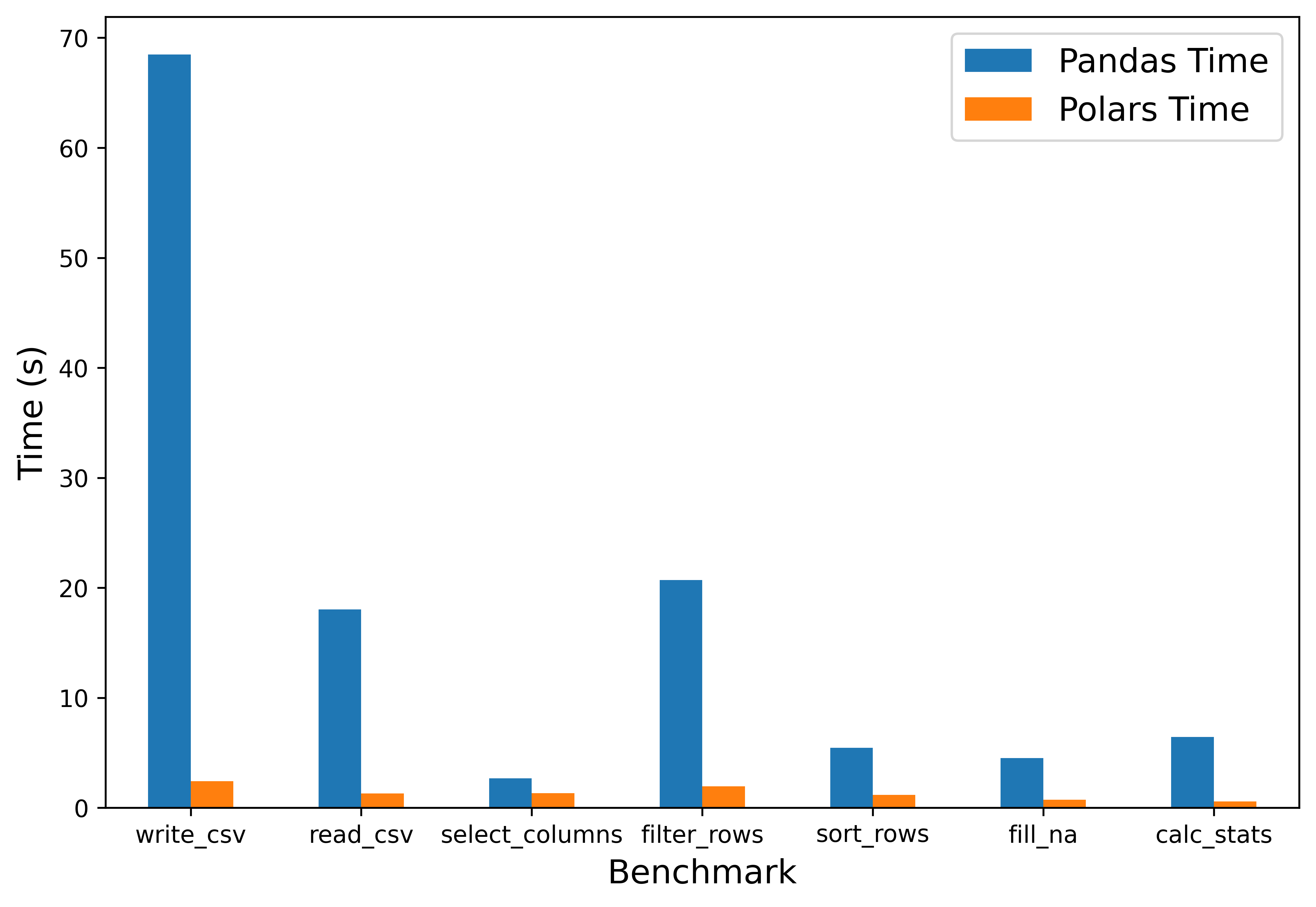 性能对比
性能对比
示例代码
在 Google
Colab 运行代码或下载 Jupyter
Notebook。
1 数据生成与存储速度比较
使用 Numpy 生成随机矩阵,构建 DataFrame,并存储为 csv 文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
print('Comparison of dataframes writing')
if not os.path.exists('./random_dataframe/'):
os.mkdir('./random_dataframe/')
start = time.perf_counter()
columns = [f'{i}' for i in range(1000)]
for i in range(10):
array = np.random.rand(10000,1000) + i * 100
df = pd.DataFrame(array, columns=columns)
df.to_csv(f'./random_dataframe/{i+1}.csv')
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
columns = [f'{i}' for i in range(1000)]
for i in range(10):
array = np.random.rand(10000,1000) + i * 100
df = pl.DataFrame(array, schema=columns)
df.write_csv(f'./random_dataframe/{i+11}.csv')
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of dataframes writing
Pandas Time: 68.47109769999952 seconds
Polars Time: 2.4320810999997775 seconds
|
2 数据读取速度比较
从 csv 文件读取 DataFrame。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
print('Comparison of dataframes reading')
start = time.perf_counter()
for i in range(20):
df = pd.read_csv(f'./random_dataframe/{i+1}.csv')
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(20):
df = pl.read_csv(f'./random_dataframe/{i+1}.csv')
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of dataframes reading
Pandas Time: 18.033977799997956 seconds
Polars Time: 1.293282899998303 seconds
|
3 数据按列选择速度比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
print('Comparison of select columns')
df_dict_pl = {}
df_dict_pd = {}
for i in range(20):
df_pl = pl.read_csv(f'./random_dataframe/{i+1}.csv')
df_dict_pl[i] = df_pl
df_pd = df_pl.to_pandas()
df_dict_pd[i] = df_pd
start = time.perf_counter()
for i in range(20000):
df = df_dict_pd[i%20]
df = df[['0','1','2','3','4']]
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(20000):
df = df_dict_pl[i%20]
df = df.select(['0','1','2','3','4'])
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of select columns
Pandas Time: 2.6878174000012223 seconds
Polars Time: 1.3185502999986056 seconds
|
4 数据筛选速度比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
print('Comparison of filter rows')
df_dict_pl = {}
df_dict_pd = {}
for i in range(20):
df_pl = pl.read_csv(f'./random_dataframe/{i+1}.csv')
df_dict_pl[i] = df_pl
df_pd = df_pl.to_pandas()
df_dict_pd[i] = df_pd
start = time.perf_counter()
for i in range(2000):
df = df_dict_pd[i%20]
df = df[df['0'] > 0.5]
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(2000):
df = df_dict_pl[i%20]
df = df.filter(df['0'] > 0.5)
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of filter rows
Pandas Time: 20.69887430000381 seconds
Polars Time: 1.9661064000029 seconds
|
5 数据排序速度比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
print('Comparison of sort rows')
df_dict_pl = {}
df_dict_pd = {}
for i in range(20):
df_pl = pl.read_csv(f'./random_dataframe/{i+1}.csv')
df_dict_pl[i] = df_pl
df_pd = df_pl.to_pandas()
df_dict_pd[i] = df_pd
start = time.perf_counter()
for i in range(200):
df = df_dict_pd[i%20]
df = df.sort_values(by='0')
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(200):
df = df_dict_pl[i%20]
df = df.sort('0')
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of sort rows
Pandas Time: 5.450892100001511 seconds
Polars Time: 1.174701100004313 seconds
|
6 数据填补速度比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
print('Comparison of fill na')
df_dict_pl = {}
df_dict_pd = {}
for i in range(20):
df_pl = pl.read_csv(f'./random_dataframe/{i+1}.csv')
df_dict_pl[i] = df_pl
df_pd = df_pl.to_pandas()
df_dict_pd[i] = df_pd
for i in range(20):
df_pd = df_dict_pd[i]
df_pl = df_dict_pl[i]
for j in range(1000):
indexes = np.random.randint(0,10000,100)
df_pd.loc[indexes,f'{j}'] = np.nan
df_pl[indexes, f'{j}'] = np.nan
df_dict_pd[i] = df_pd
df_dict_pl[i] = df_pl
start = time.perf_counter()
for i in range(200):
df = df_dict_pd[i%20]
df = df.fillna(0)
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(200):
df = df_dict_pl[i%20]
df = df.fill_null(0)
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of fill na
Pandas Time: 4.529551200001151 seconds
Polars Time: 0.7351737999997567 seconds
|
7 数据统计量计算速度比较
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
print('Comparison of calculate dataframes statistics')
df_dict_pl = {}
df_dict_pd = {}
for i in range(20):
df_pl = pl.read_csv(f'./random_dataframe/{i+1}.csv')
df_dict_pl[i] = df_pl
df_pd = df_pl.to_pandas()
df_dict_pd[i] = df_pd
start = time.perf_counter()
for i in range(20):
df = df_dict_pd[i%20]
df.mean()
df.var()
df.std()
df.sum()
df.max()
df.min()
df.median()
df.quantile(0.25)
df.quantile(0.75)
end = time.perf_counter()
print(f'Pandas Time: {end - start} seconds')
start = time.perf_counter()
for i in range(20):
df = df_dict_pl[i%20]
df.mean()
df.var()
df.std()
df.sum()
df.max()
df.min()
df.median()
df.quantile(0.25)
df.quantile(0.75)
end = time.perf_counter()
print(f'Polars Time: {end - start} seconds')
|
输出:
1
2
3
| Comparison of calculate dataframes statistics
Pandas Time: 6.443044399995415 seconds
Polars Time: 0.5910871000014595 seconds
|